Computer Vision: Face Recognition
10 minutes read
- What is face recognition?
- What is face verification evaluation protocol?
- How is face verification solved?
- What is a triplet loss training scheme?
- What is the re-identification problem?
- What are some challenges in person re-identification?
- What are some approaches to person re-identification?
- What is facial key-point regression?
- What are some approaches to key-point regression tasks?
- How to build a statistical model of facial shape?
What is face recognition?
Face recognition performance is reported in three standard tasks:
-
Verification: Two facial images are presented to a system. The system has to decide if the images belong to the same person or to two different persons. This is also called one to one matching. The basic question is, is this person who he claims to be?
-
Open set identification: Build up on verification but extend its formulation. The basic question asked is do we know this face? and the person doesn’t have to be somebody in the gallery.
-
Closed set identification: Is the classic performance measure used in automatic face recognition. The basic question asked is whose face is this? and the person is someone in the gallery
What is Face verification evaluation protocol?
- An image $p_j$ is presented to the system with gallery G
- Similarity scores $s_{ij}$ are computed
- Verification rate for gallery probes $p_j \in P_G:$
- False accept rate for non gallery probes $p_j \in P_N:$
How is face verification solved?
Large scale open set identification tasks bear similarity to the Content Based Image Recognition task, but are restricted to the domain of facial images only.
Following are the standard stages of face verification:
- The face is detected on the image and its bounding boxes are cropped.
- The face undergoes alignment to march a certain normalized representation. The reason we do this is because many facial recognition algorithms including deep learning and metric methods can all benefit from applying facial alignment before trying to identify the face.
- A deep convolutional neural network is applied to extract a feature vector from the facial image.
- In the same way this was performed in the CBIR task. SUch a feature vector is compared against all feature vectors corresponding to the images in the gallery to find the closest match.
Initially, the deep architecture fee are bootstrapped by considering the problem of recognizing several thousand unique individuals set up as a multiclass classification problem. After learning, a classifier layer can be removed and the score of actors can be used for face identity verification using the Euclidean distance to compare them. However, the scores can be significantly improved by tuning them for verification in the Euclidean space using a triplet loss training scheme.
What is a triplet loss training scheme?
A triplet consists of 2 matching and 1 non-matching thumbnail images.
- Embed input image X into Euclidean space $\mathbb{R}^d$ via f(x)
-
We want $ f(a) - f(p) _2^2 + \alpha < f(a) - f(n) _2^2$ - Minimize triplet loss:
What is the re-identification problem?
Person re-identification is the problem of identifying people across images that have been taken using different cameras or across time using a single camera.
What are some challenges in person re-identification?
- The resolution of person images are very low since they are captured by surveillance cameras
- Lighting conditions are unstable.
- The direction of cameras and the pose of persons are arbitrary.
- Human pose across time and space
- background clutter and occlusions.
- Different individuals sharing the same appearance.
What are some approaches to person re-identification?
A standard approach to re-identification generally follows the pipeline sent by face verification algorithms. A typical re-identification system takes as input two images, each of which usually contains a person’s full body. And outputs, either a similarity score between the two images or a classification of the pair of images as same if the two images depict the same person, or different if the images are of different people.
Given two person images, they are sent to Siamese convolutional neural network. A neural network architecture which consists of two copies of the same network.
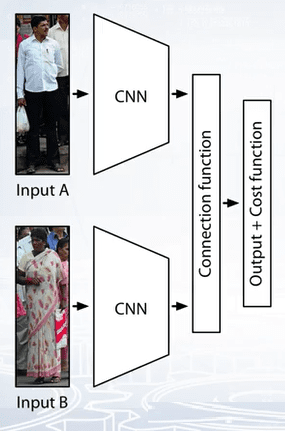
For two images, x and y, a Siamese network can predict a label to denote whether the image pair comes from the same subject or not. Siamese network is composed of two convolutional neural networks connected by a connection function. Connection function is used to evaluate the relationship between two samples. And cost function is used to convert the relationship into a cost.
How to choose the connection function and cost function is closely related to the performance of the re-identification model. There are many distance, similarity or other functions that can be used as candidates to connect to vectors such as euclidean distance, cosine similarity, absolute difference, vector concatenation and so on.
What is facial key-point regression?
The objective of key-points regression task is to predict or regress onto positions of certain important locations on face images. Key-points are used as a building block in several applications such as tracking faces in images, in video, analyzing facial expressions, detecting dysmorphic facial signs for medical diagnosis, and biometrics or face recognition.
What are some approaches to key-point regression tasks?
Approaches to keypoint regression can be generally divided into two categories.
- Classify local search windows or,
- Directly predicting keypoint locations, or shape perimeters for entire image. This bears significant similarity to attribute recognition approaches.
For the first category, a classifier called facial part detector is trained for each keypoint and keypoint location is predicted based on local regions.
There are two matters one has to decide upon:
- How to construct local detectors for each face part.
- How to choose right candidate among all outputs predicted as positives by local detectors.
To start with, for each face part, such as eyes, or mouth, we can construct local detectors. Such a detector utilizes a sliding window to search for a location in the image containing the facial part. For each position of the sliding window, image features such as CNN features, or HOG features are extracted and then classified as related or not related to the facial part.
The second step in recognition would be to gather them into a complete facial shape. We can formulate facial part localization as a bayesian inference that combines the output of local detectors with a prior model of face shape and build a statistical model of facial shape.
How to build a statistical model of facial shape?
-
Point distribution model: scatter keypoints to represent shapes as a sequence of connected landmarks or points in the surface of a face. $x = (x_1 \dots , x_n, y1, \dots , y_n)^T$
-
Represent any shape x via approximation $x = \bar{x} + P_s b_s$ places landmarks at unique boundary locations such as salient points on the boundary curves.
-
Training: apply PCA to labeled images $\rightarrow \bar{x}, P_s, b_s$ helps us answer a few questions such as, what does the average shape looks like and what kinds of variations are normal
To compute a prior model of facial shape, we can use active shape or active appearance models. In active shape model a point distribution model captures the shape variants and gradient distributions for a set of facial keypoints, and describes the local appearance. The shape of the face can then be defined as that property of the configuration of points which is kept unchanged or invariant under some global transformation.
Couple of disadvantages of active shape model are, one, the initial shape may be far from the target position, and the update may end up being in a local minimum. And two, visual features extracted at each step are not discriminative or not reliable enough to predict facial points.
️⭐️ Next Post: Computer Vision: Object Detection
Read about Computer Vision: Object Detection.
If you need more explanations, have any doubts or questions, you can comment below or reach out to me personally via Facebook or LinkedIn, I would love to hear from you 🙂.
🔔 Subscribe 🔔 so you don’t miss any of my future posts!